Reducing AWS Costs by 50+%
How I cut the AWS bill in more than half with minimal downtime.
My client was facing a large AWS bill that was hard to justify based on the number of active users. Either there was an unusual source of waste, or the system was significantly overprovisioned.
I started by reviewing the AWS cost dashboard. The majority of the spend was coming from RDS, with ECS as a distant second. Since RDS was the largest cost driver, I focused there first.
The system was using Aurora Serverless v2, and two issues stood out immediately.
First, the minimum ACU settings were overprovisioned. The usage graphs showed the databases sitting at their minimum capacity almost all the time.
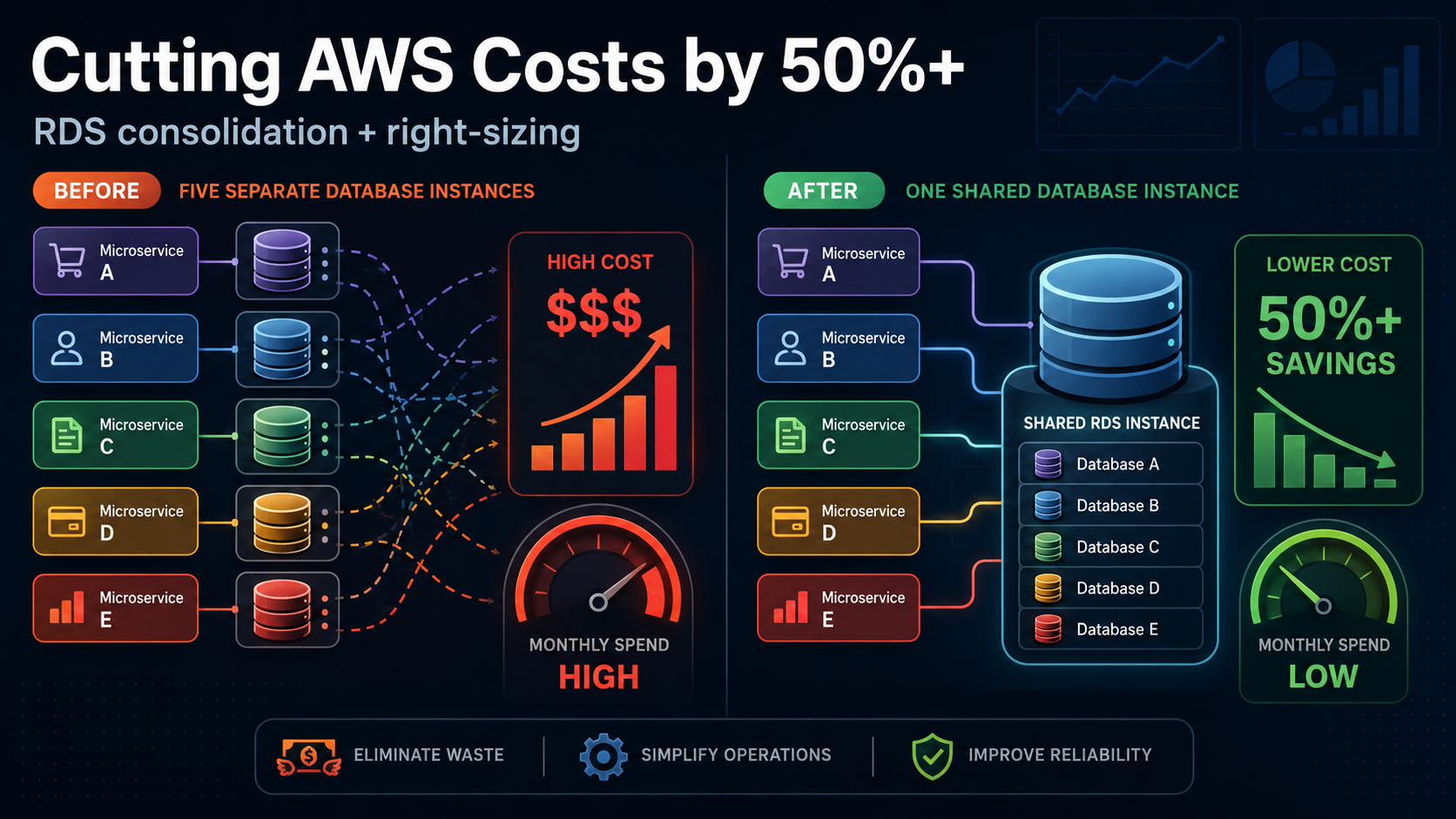
Second, the system had five microservices, and each service had its own database instance. For this particular system and its business needs, that separation was unnecessary. The services still needed separate databases, but they did not need separate servers.
The first fix was straightforward. I lowered the minimum ACU settings and tested the impact. Setting the minimum to 0.5 ACUs can be tempting because it is the lowest possible value, but it can also affect performance. After some experimentation, I found that setting the minimum to 1 ACU across the instances gave us the best cost-benefit tradeoff.
With the quick savings done, I moved to the larger opportunity: consolidating the five database instances into one shared instance, with one database per microservice. This would reduce the instance-related portion of RDS costs by roughly 80%.
I updated the infrastructure-as-code setup to create the shared instance and provision one database for each service. The remaining work was migrating the data from the old databases to the new ones.
A migration like this can be done without downtime, but it adds complexity and takes more time. Since the system already had a maintenance mode feature, we decided it was better to move quickly and accept a short, planned downtime window.
I wrote a migration script, tested the full process in staging, and created a production migration checklist. I also left a pull request ready to update each microservice’s connection string. Once that PR was merged, CI/CD would deploy the services and point them to the new databases.
The production checklist was:
- Enable the maintenance mode feature flag.
- Log in to the VPN to access the databases.
- Run the migration script.
- Merge the prepared PR and wait for deployment to finish successfully (this implied that services were healthy and able to connect to their respective databases).
- Run a production smoke test with an internal user, since internal users could bypass maintenance mode.
- Disable the maintenance mode feature flag.
The migration went smoothly. After it was done, I deleted the old instances. There was also a PR ready to be merged to make this happen.
Once RDS had been optimized, I moved on to ECS. The same pattern showed up there: the services were allocated far more CPU and memory than they needed. I reduced those allocations to better match actual usage.
Together, these changes cut the AWS bill by more than half, saving the company thousands of dollars per month.